Apache Iceberg
Apache Iceberg is an open table format for huge, slow-changing, analytic data-sets. Iceberg aims to support the following:
- Schema evolution with no side effects
- Hidden partitioning to avoid performance penalties and user error
- Partition layout evolution as data and patterns evolve over time
- Time travel to reproduce historical queries
- Version rollback to correct problems by resetting to a known good state
- Readers isolated from concurrent writes
- Writers add and remove files atomically
- Planning and scanning takes
O(1)and is not impacted by table size
Because Iceberg has been designed for large data-sets it can be used in production where a single table is measured in petabytes. Iceberg is also designed to solve correctness problems in eventually-consistent cloud object stores. It is cloud platform agnostic, table changes are atomic so readers never see partial changes, and concurrent writers when experiencing conflicts will retry to ensure updates are compatible.
Overview
Performance
- What problem is Iceberg trying to solve?
- huge tables where a single table can contain multiple petabytes of data
- reading huge tables using only a single node
- How does scan planning work in Iceberg?
- scan planning is finding the files in a table needed for a query
- planning works on single nodes
- metadata can be used to prune metadata files that aren’t needed
- metadata can be used to filter data files that don’t contain matching data
- results in low latency SQL queries
- can be accessed by any client
- How does metadata filtering work?
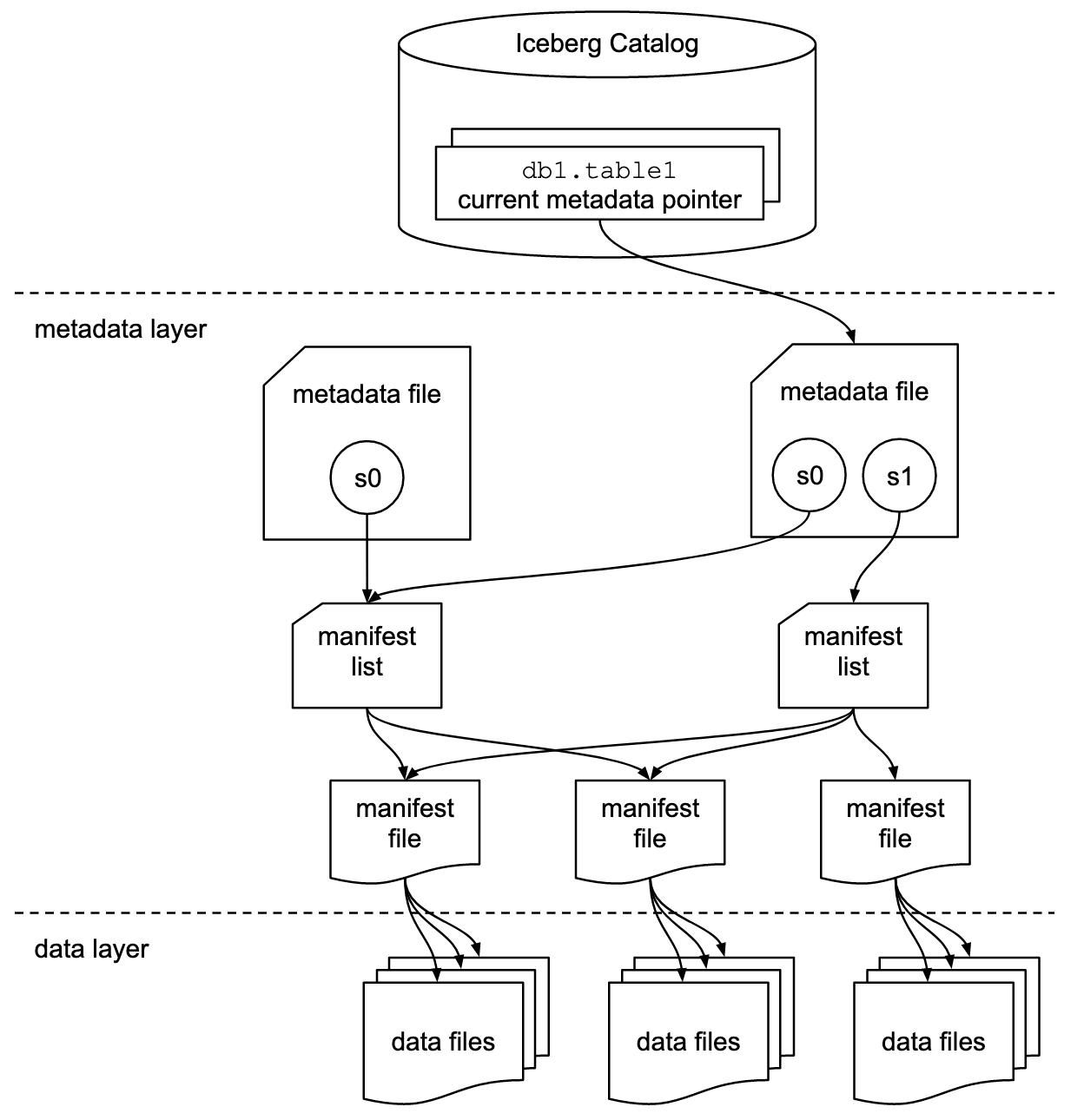
- there are two levels of metadata
- Manifest files
- reused across snapshots
- store a list of data files
- store each data files partition data
- stores column level stats for a data file
- value counts, distinct values in this column
- null counts, null values in this column
- lower bounds, smallest value in this column
- upper bounds, largest value in this column
- Manifest lists
- stores a snapshots list of manifest files
- stores a partition stats
- range of partition values
- stores data file counts
- helps speed up operations like snapshot expiration
- How does this enable fast scan planning?
- manifest list acts as an index over the manifest files
- filters manifests using the partition value range
- reads remaining manifests to get data files
- How does data filtering work?
- manifest files contain a tuple of partition data and column-level stats for each data file
- broad phase query planning
- query conditions are checked against partition data
- narrow phase query planning
- column-level stats filter out even more data files
- value counts
- null counts
- lower bounds
- upper bounds
- column-level stats filter out even more data files
Reliability
- How reliable is Iceberg?
- Iceberg was designed to solve correctness problems
- tracks the complete list of data files in each snapshot
- using a persistent tree structure
- every write/delete produces a new snapshot
- reuses previous snapshots metadata tree to avoid high write volumes
- table metadata file
- reference to current snapshot
- list of all valid snapshots
- commits replace the path of the current table metadata atomically
- reliability guarantees
- all table changes occur in linear history of atomic table updates
- readers always use a consistent snapshot of the table without using locks
- table snapshots are kept as history
- tables can roll back if a job produces bad data
- supports safely compacting small files
- supports safely appending late data to tables
- performance benefits
O(1)RPC calls to plan instead of listingO(n)directories- file pruning and predicate push-down is distributed
- removes barriers to finer-grained partitioning
- How do concurrent write operations work?
- Iceberg uses optimistic concurrency
- Each writer
- assume no other writer is operating
- write out new table metadata for the operation
- attempts to commit by atomically swapping the existing table metadata file with the new metadata file
- What if this fails?
- retry with a new metadata file based on the updated current table state
- How expensive are retries?
- expensive retries are avoided by structuring changes that can be reused
- new manifest files that can be applied independent of the current state
- expensive retries are avoided by structuring changes that can be reused
- How are retries validated?
- commits are structured with assumptions and actions
- on conflict
- check if assumptions are still met
- if they are
- re-apply actions and commit
- if not
- the operation fails
- How is Iceberg made to be compatible?
- avoiding file listing and rename operations
Catalog
- What is a Catalog?
- a way to track tables by name
- is responsible for creating, dropping, and renaming tables
- manages a collection of tables that can be grouped into namespaces
- tracks a table’s current metadata
- provided to the catalog on loading the table
- first step using an Iceberg client is initializing a catalog
- used by compute engines to execute catalog operations
- multiple types of compute engines can share an Iceberg catalog
- allows them to share a common data layer
Partitioning
- What is partitioning?
- grouping similar rows together when writing
- speeds up queries
- What type of partitioning does Iceberg support?
- timestamps can be partitioned by year, month, day, or hour
- other columns can be used to categorically partition
- How does Iceberg do partitioning differently?
- supports hidden partitioning
- produces partition values for rows
- automatically avoids reading unnecessary partitions
- supports evolving partition layouts
- Why do hidden partitioning?
- Iceberg creates partition values by taking a column value and optionally transforming it
- This work is offloaded from the user to Iceberg
- Producers and consumers do not need to be aware of the partition value
- Queries do not depend on the physical table layout
- Allows for misconfigured tables to be fixed without having to migrate
Branching & Tagging
- Why do Iceberg tables maintain snapshots?
- Tracking all table changes
- Enables time travel queries
- Isolates readers from any partial changes
- Snapshots can be set to expire to control storage size and cost
- Why does Iceberg support branches and tags?
- Allows references to snapshots that have an independent life cycle
- Life cycle is controlled at the branch and tag level
- Branches/tags have a max age property for when the reference should expire
- Branches can define min number of snapshots to retain on branch
- Branches can define max age of snapshots to retain on branch
- These properties are used when running
expireSnapshots()
- Why would you want to use branches or tags?
- Handling GDPR requirements
- Branches
- creating experimental branches for testing
- Tags
- retaining historical snapshots for audits
- retain weekly snapshot for a month
- retain monthly snapshot for 6 months
- retain annual snapshot forever
- retaining historical snapshots for audits
- Why does the schema matter for branches and tags?
- The table schema is valid across all branches
- When writing data to a branch the table’s schema is used
- This could potentially make column data invalid/NULL in a branch
- When querying a tag, the snapshot’s schema is used
- Snapshots reference a schema upon creation
Evolution
- What is evolution in Iceberg?
- in-place table evolution
- it is table schema changes
- it is nested structure changes
- it is new partition layout changes
- all of this without rewriting the table data or migrating to a new table
- What is schema evolution?
- Adding new columns, nested struct field
- removing existing columns, nested struct field
- renaming existing columns, nested struct field
- updating the type of a column, nested struct field, map key/value, or list element
- reordering columns or nested struct fields
- How does schema evolution work?
- Modifying the table metadata
- This requires no data files to be rewritten
- Modifying the table metadata
- What is schema evolution correctness?
- schema evolution changes are independent with no side effects
- added columns don’t read existing values from another column
- dropped columns/fields does not modify the values in another column
- updating a column/field does not modify the values in another column
- changing the order of columns/fields does not change the associated values
- each column in a table has a unique id
- How does partition evolution work?
- queries do not reference partition values directly
- What happens on partition evolution?
- old data remains unchanged
- new data is written using the new layout
- independent metadata for each partition is stored
- Why is this useful?
- queries get split planning
- each partition layout plans files separately using its own derived filter
- allows multiple partition layouts to exist in the same table
- hidden so queries don’t need to consider this abstraction
- exists at the metadata level
- does not eagerly rewrite files
- How does sort order evolution work?
- old data remains unchanged
- new data will respect the new sort order
- engines can chose to write data unsorted if sorting becomes too expensive
- some engines can update the sorting order of old data
Maintenance
- Why is expiring snapshots recommended?
- each write to an iceberg table creates a snapshot of the table
- these snapshots will accumulate
- snapshots can be expired using
expireSnapshots() - this reduces the size of table metadata
- data files are deleted when no snapshot references them
- How does this impact time travel and rollbacks?
- snapshot is no longer in metadata so it cannot be queried
- cannot rollback since unused data files will be deleted
- Why remove old metadata files?
- every change to a table creates a new metadata file
- old metadata files are kept by default to preserve history
- tables with frequent commits will need to regularly clean metadata files
- ingesting streaming data
- table properties can be set to clean metadata files
- cleaning will not delete orphaned metadata files
- it is recommended to clean old metadata files
- What are orphan files?
- a failed job can create files that are unreferenced by table metadata
- normal snapshot expiration sometimes is unable to determine if an orphan file can be cleaned up
- How can I clean up orphan files?
deleteOrphanFiles()will remove all orphaned files in an iceberg table- this can take a long time to finish
- it is recommended to be run periodically
- When is removing orphan files dangerous?
- with a very short retention interval (default is 3 days)
- during write operations that last longer than the retention interval
- this could lead to deleting files part of a write in progress
- this could potentially corrupt the table
- Why should you compact data files?
- each data file is tracked in iceberg
- more data files leads to more metadata stored in manifest files
- many small files leads to large amounts of metadata
- opening many small files adds a performance penalty
- compacting files with
rewriteDataFiles()reduces these problems
- Why should you rewrite manifests?
- Iceberg has metadata in its manifest list and manifest files
- speeds up query planning and data file pruning
- metadata tree compacts manifests automatically in the order they are added
- makes queries faster when table writes align with query patterns
- What happens when the write pattern does not align with query patterns?
- rewrite metadata to re-group data files into manifests
rewriteManifests()does this
- Iceberg has metadata in its manifest list and manifest files
Metrics Reporting
- What are scan reports?
- report for scan planning against a table
- scan duration
- number of data/delete files included in result
- number of data/delete files scanned or skipped
- number of manifests scanned or skipped
- number of equality/positional delete files scanned
- report for scan planning against a table
- What is a commit report?
- report for committing changes against a table
- total duration
- number of attempts required for commit to succeed
- number of added/removed data/delete files
- number of added/removed equality/positional delete files
- number of added/removed equality/positional deletes
- report for committing changes against a table
Schemas
| Type | Description | Notes |
|---|---|---|
boolean |
True or false | |
int |
32-bit signed integers | Can promote to long |
long |
64-bit signed integers | |
float |
32-bit IEEE 754 floating point | Can promote to double |
double |
64-bit IEEE 754 floating point | |
decimal(P,S) |
Fixed-point decimal; precision P, scale S | Scale is fixed and precision must be 38 or less |
date |
Calendar date without timezone or time | |
time |
Time of day without date, timezone | Stored as microseconds |
timestamp |
Timestamp without timezone | Stored as microseconds |
timestamptz |
Timestamp with timezone | Stored as microseconds |
string |
Arbitrary-length character sequences | Encoded with UTF-8 |
fixed(L) |
Fixed-length byte array of length L | |
binary |
Arbitrary-length byte array | |
struct<...> |
A record with named fields of any data type | |
list<E> |
A list with elements of any data type | |
map<K, V> |
A map with keys and values of any data type |
Glossary
- Schema Names and types of fields in a table
- Partition spec A definition of how partition values are derived from data fields
- Snapshot The state of a table at some point in time, including the set of all data files
- Manifest list A file that lists manifest files; one per snapshot
- Manifest A file that lists data or delete files; a subset of a snapshot
- Data file A file that contains rows of a table
- Delete file A file that encodes rows of a table that are deleted by position or data values